Development of Algorithms for Biotechnology and Biomedical Applications
Overview
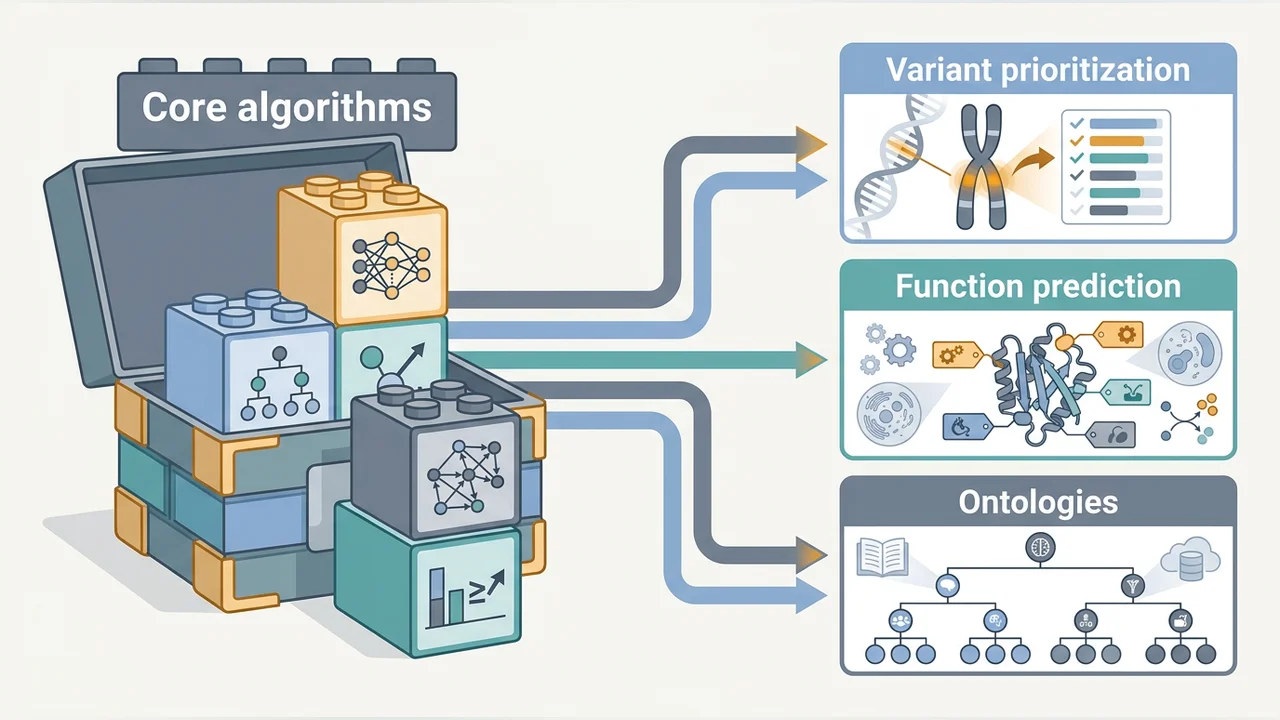
This CBRC Competitive Funding project (2021–2023, run under the now-dissolved Computational Bioscience Research Center) functioned as an umbrella program for algorithm development across the group's biotechnology and biomedical work, with a deliberate focus on metabolic modeling — predicting metabolic function from genome, predicting interactions from structure, and learning from interaction networks to identify disease-relevant biology. The unifying scientific bet was that systems biology requires algorithms that operate not on isolated molecules but on the networks of interactions within and between organisms, and that machine learning over those networks should respect the ontological structure of biological knowledge rather than treat it as opaque tabular data.
The first pillar was metabolic function prediction. Standard deep-learning protein-function predictors fail on the long tail: any function with fewer than roughly 100 characterized examples becomes unpredictable, and many metabolic functions are exactly in that regime. We developed DeepGOZero, a neuro-symbolic extension of the DeepGO architecture that uses model-theoretic semantics of the Gene Ontology to predict functions for which not a single positive training example exists — zero-shot prediction grounded in the ontology's logical axioms rather than statistical regularities. Building on this, Predicting protein functions using positive-unlabeled ranking with ontology-based priors (2024) reformulated function prediction as a positive-unlabeled learning problem, which is the realistic statistical model for biological annotation data (absence of annotation rarely means absence of function), and showed material improvements over the prior state of the art for rare functions.
From single proteins to interaction networks
The second pillar shifted scale from single proteins to interactions and pathways. Because the number of possible pairwise interactions grows quadratically with proteome size, naive prediction is intractable. We introduced an ontology-based filter that uses DeepGO's cellular-component predictions to rule out pairs of proteins located in incompatible compartments, reducing the candidate space roughly tenfold per organism at high accuracy. DeepGOMeta: functional insights into microbial communities with deep learning-based protein function prediction (2023) carried these methods into the metagenomic setting, providing function-level comparisons between microbial communities that downstream metabolic-modeling work depends on. Context-based protein function prediction in bacterial genomes (2022) added genomic-neighbourhood information as a complementary signal, sharpening predictions for bacteria where homology-based methods alone are inadequate.
The third pillar was learning over biological networks. DeepMOCCA applied graph neural networks with attention to integrated metabolic and protein–protein interaction networks of human metabolism (Virtual Metabolic Human, STRING) combined with multi-omics measurements; graph attention prioritized the metabolites driving the distinction between case and control samples. The main limitation — too few large multi-omics datasets to exercise the architecture — motivated the group's sampling of Red Sea seawater for untargeted metabolomics, which seeded later marine-metabolism work.
Underpinning all three pillars, the project produced infrastructure and methodology papers that the wider field has adopted. mOWL (2022) is the Python library that operationalises machine-learning with OWL ontologies and is now used by external groups for ontology-aware ML pipelines. Ontology embedding: a survey of methods, applications and resources classified the rapidly growing family of ontology-embedding methods and identified which methods preserve which semantic properties. Large-scale knowledge integration for enhanced molecular property prediction (2022) demonstrated that embedding biomedical knowledge graphs into molecular-property predictors improves performance on drug-discovery benchmarks; How much do model organism phenotypes contribute to the computational identification of human disease genes? (2021) quantified the contribution of mouse, fish, fly, and yeast phenotype data to human disease-gene prediction. STARVar and the Klarigi-derived explanation work extended the algorithmic stack toward symptom-based variant ranking and human-interpretable outputs.
The aggregate contribution is a coherent algorithmic stack — zero-shot function prediction, ontology-filtered interaction prediction, graph-neural-network learning over metabolic and PPI networks, and tooling (mOWL, ontology embeddings) that makes these methods usable beyond the group. PhD work by Sumyyah Toonsi was developed within this program. The methods produced here became the algorithmic backbone for several follow-on CBRC efforts, including the Saudi Pangenome work, the CoE-GenAI BCB theme, and the desert-microbiome project.
Period: 2021–2023
Funding
- KAUST Center Competitive Fund
— Grant ID:
FCC/1/1976-34-01(PI) — USD 360,000
Team
- Robert Hoehndorf — PI (KAUST (Professor of Computer Science))
- Sumyyah Toonsi — PhD (alumnus)
Publications acknowledging this project (6)
- (2025) The application of Large Language Models to the phenotype-based prioritization of causative genes in rare disease patients [live]
- (2025) Ontology Embedding: A Survey of Methods, Applications and Resources [live]
- (2024) Large-Scale Knowledge Integration for Enhanced Molecular Property Prediction [live]
- (2023) Exploring the Use of Ontology Components for Distantly-Supervised Disease and Phenotype Named Entity Recognition
- (2023) Improving the classification of cardinality phenotypes using collections [live]
- (2023) Starvar: symptom-based tool for automatic ranking of variants using evidence from literature and genomes [live]
Topics: Neuro-symbolic AI
Related People
Related Researchers


Sumyyah Toonsi
- Ph.D. Student (former), Computer Science