Bio2Vec: Smart analytics infrastructure for the life sciences
Overview
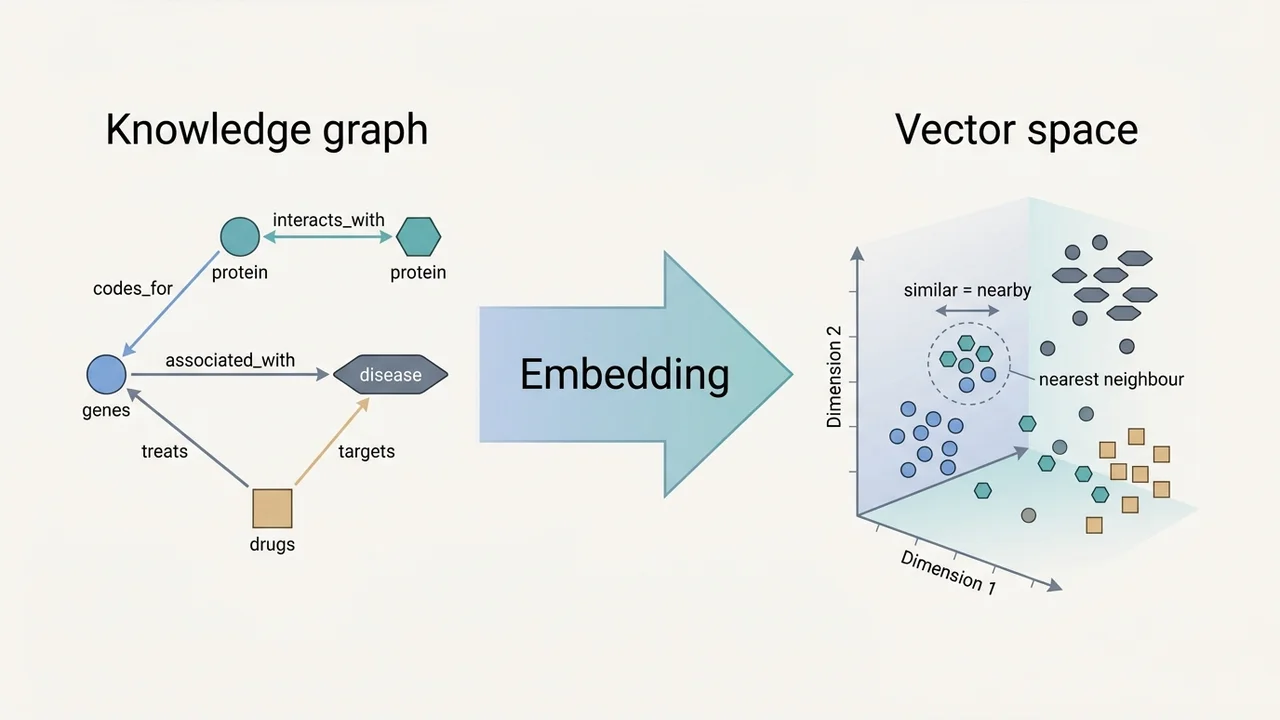
By the mid-2010s the life sciences had produced an extraordinary investment in machine-readable knowledge: biomedical ontologies were used throughout biology to annotate data, and large RDF knowledge graphs such as Bio2RDF aggregated billions of statements from dozens of major databases. At the same time, large personal genomic datasets, the UK 100,000 Genomes project, UK Biobank, and the Saudi Human Genome Program, were coming online, and translating these into clinical insight depended on integrating them with that existing background knowledge. Generic knowledge-graph machine learning methods, however, did not handle either the size or the rich Description Logic semantics of biomedical knowledge graphs, and computational biologists still spent most of their time integrating and cleaning data instead of analyzing it. Bio2Vec, a CRG2017-funded collaboration with Stanford/Maastricht (Michel Dumontier), KAUST (Xin Gao), and Bonn (Jens Lehmann) running 2018-2020, set out to build the missing semantic analytics infrastructure for the life sciences.
The technical legacy of the project is a family of ontology- and knowledge-graph embedding methods that have become standard tools. Onto2Vec: joint vector-based representation of biological entities and their ontology-based annotations (Bioinformatics, 2018) was the first method to learn entity representations that jointly capture an ontology's axioms and the data annotated with it, and it outperformed semantic-similarity baselines on protein-protein interaction and gene-disease association tasks. OPA2Vec: combining formal and informal content of biomedical ontologies to improve similarity-based prediction (Bioinformatics, 2018) extended this to use both formal axioms and the natural-language annotations (labels, definitions, synonyms) attached to ontology classes. EL Embeddings: Geometric construction of models for the Description Logic EL++ (IJCAI 2019) was, to the team's knowledge, the first method to construct embeddings of an ontology that are provably sound with respect to the model theory of the underlying logic, opening up a line of work on syntax-semantics-preserving embeddings that continues in subsequent projects. Vec2SPARQL: integrating SPARQL queries and knowledge graph embeddings (SWAT4LS 2018) showed how to combine logical retrieval with vector similarity in a single query language, and Semi-Supervised Entity Alignment via Knowledge Graph Embedding with Awareness of Degree Difference (WWW 2019) addressed cross-graph alignment, a perennial integration headache.
The infrastructure was tied to concrete biomedical use cases. DeepGOPlus: improved protein function prediction from sequence (Bioinformatics, 2020) used learned ontology structure to deliver competitive function prediction from sequence alone, and was complemented by DeepPheno: Predicting single gene loss-of-function phenotypes using an ontology-aware hierarchical neural network (PLOS Computational Biology, 2020) for phenotype prediction. DeepPVP: phenotype-based prioritization of causative variants using deep learning (BMC Bioinformatics, 2019) and OligoPVP: Phenotype-driven analysis of individual genomic information to prioritize oligogenic disease variants (Scientific Reports, 2018) applied the framework to variant prioritization; Ontology-based prediction of cancer driver genes (Scientific Reports, 2019) to cancer genomics; and PathoPhenoDB: linking human pathogens to their disease phenotypes (Scientific Data, 2019) to infectious disease research. The methodological synthesis is captured in Semantic similarity and machine learning with ontologies (Briefings in Bioinformatics, 2020), which has become a widely cited reference in the area.
Bio2Vec delivered both an infrastructure (the embedding stack, the analytics methods built on SANSA, the integration with Bio2RDF and the AberOWL ontology repository) and a body of evidence that semantic background knowledge measurably improves prediction on real biomedical problems. The methods opened the way for everything that followed in the group's neuro-symbolic line, including IBNSINA-QI, the CRG11 explainable-ML project, and the function-prediction stack used in DeepGOMeta and DeepGOZero. For Saudi Arabia, the project produced reusable, knowledge-based analytics that fit the Vision 2030 transition to a knowledge-based economy and laid the technical groundwork for population-scale genomics applications that came online in subsequent projects.
Period: 2018–2020
Funding
- KAUST Competitive Research Grant
— Grant ID:
URF/1/3454-01-01(PI) — USD 113,250
Team
- Robert Hoehndorf — PI (KAUST (Professor of Computer Science))
- Xin Gao — CoI (KAUST (formerly CBRC, now dissolved))
- Michel Dumontier — CoI (Maastricht University)
- Jens Lehmann — CoI (Amazon (formerly TU Dresden))
- Mona Alshahrani — PhD (alumnus) (Jubail University College (Assistant Professor))
- Maxat Kulmanov — PhD (alumnus) (KAUST (Research Scientist))
- Sumyyah Toonsi — MSc (alumnus)
Software
- OPA2Vec — Combines ontology axioms with associated annotation properties (labels, synonyms, definitions) into a single corpus, then trains Word2Vec to produce semantically rich vectors for ontology classes. https://github.com/bio-ontology-research-group/opa2vec
- Onto2Vec — Representation learning for ontologies and their annotations by treating logical axioms as natural-language sentences; predecessor of OPA2Vec. https://github.com/bio-ontology-research-group/onto2vec
- DL2Vec — Encodes description-logic axioms as a directed graph and learns embeddings via random walks; widely used for downstream gene-disease and protein-function prediction. https://github.com/bio-ontology-research-group/DL2Vec
- Walking RDF and OWL — Original feature-learning method over RDF graphs and OWL ontologies via biased random walks; the seed implementation for many later embedding methods including OWL2Vec*. https://github.com/bio-ontology-research-group/walking-rdf-and-owl
- DeepGOPlus — CNN-ensemble protein-function predictor that augments sequence-based scoring with k-nearest-neighbour homology and GO axioms; one of the strongest CAFA-evaluated open models. https://github.com/bio-ontology-research-group/deepgoplus
- DeepGO — Original sequence-based, ontology-aware deep classifier for predicting Gene Ontology functional annotations; basis of the entire DeepGO family of tools. https://github.com/bio-ontology-research-group/deepgo
- Onto2Graph — Generates entailment-aware graph projections of OWL ontologies suitable for downstream graph machine learning while preserving the axioms' deductive structure. https://github.com/bio-ontology-research-group/Onto2Graph
- OntoFunc — Ontology-driven enrichment analysis that supports arbitrary OWL ontologies and full subsumption-aware aggregation, not only GO. https://github.com/bio-ontology-research-group/ontofunc
- vec2SPARQL — Adds embedding-similarity functions to a SPARQL endpoint so that vector-space queries (k-nearest neighbours, cosine similarity) can be mixed with classical graph patterns. https://github.com/bio-ontology-research-group/vec2sparql
- SmuDGE — Semantic disease-gene embeddings; integrates phenotype, function and pathway ontologies into a unified vector space for downstream prediction. https://github.com/bio-ontology-research-group/SMUDGE
- Multi-Drug Embedding — Drug repurposing method that learns joint embeddings of drugs, targets and diseases from biomedical knowledge graphs and the scientific literature. https://github.com/bio-ontology-research-group/multi-drug-embedding
- DeepMOCCA — Graph neural network for cancer survival analysis that integrates multi-omics (mutation, expression, methylation, CNV) with a curated cancer knowledge graph. https://github.com/bio-ontology-research-group/DeepMOCCA
Publications acknowledging this project (11)
- (2020) Combining lexical and context features for automatic ontology extension
- (2020) DDIEM: drug database for inborn errors of metabolism [live]
- (2020) DeepGOPlus: improved protein function prediction from sequence
- (2020) Formal axioms in biomedical ontologies improve analysis and interpretation of associated data
- (2019) Quantitative evaluation of ontology design patterns for combining pathology and anatomy ontologies
- (2019) Ontology-based prediction of cancer driver genes
- (2019) Ontology based mining of pathogen--disease associations from literature
- (2019) PathoPhenoDB: linking human pathogens to their disease phenotypes in support of infectious disease research [live]
- (2019) Ontology based text mining of gene-phenotype associations: application to candidate gene prediction
- (2018) Vec2SPARQL: integrating SPARQL queries and knowledge graph embeddings
- (2017) Phenotype-driven discovery of digenic variants in personal genome sequences
Topics: Applied Ontology, Neuro-symbolic AI, Semantic similarity
Related People
Related Researchers


Maxat Kulmanov
- Research Scientist (former), Bio-Ontology Research Group

Sumyyah Toonsi
- Ph.D. Student (former), Computer Science