A public Saudi pangenome as reference for genomics in the Middle East
Overview
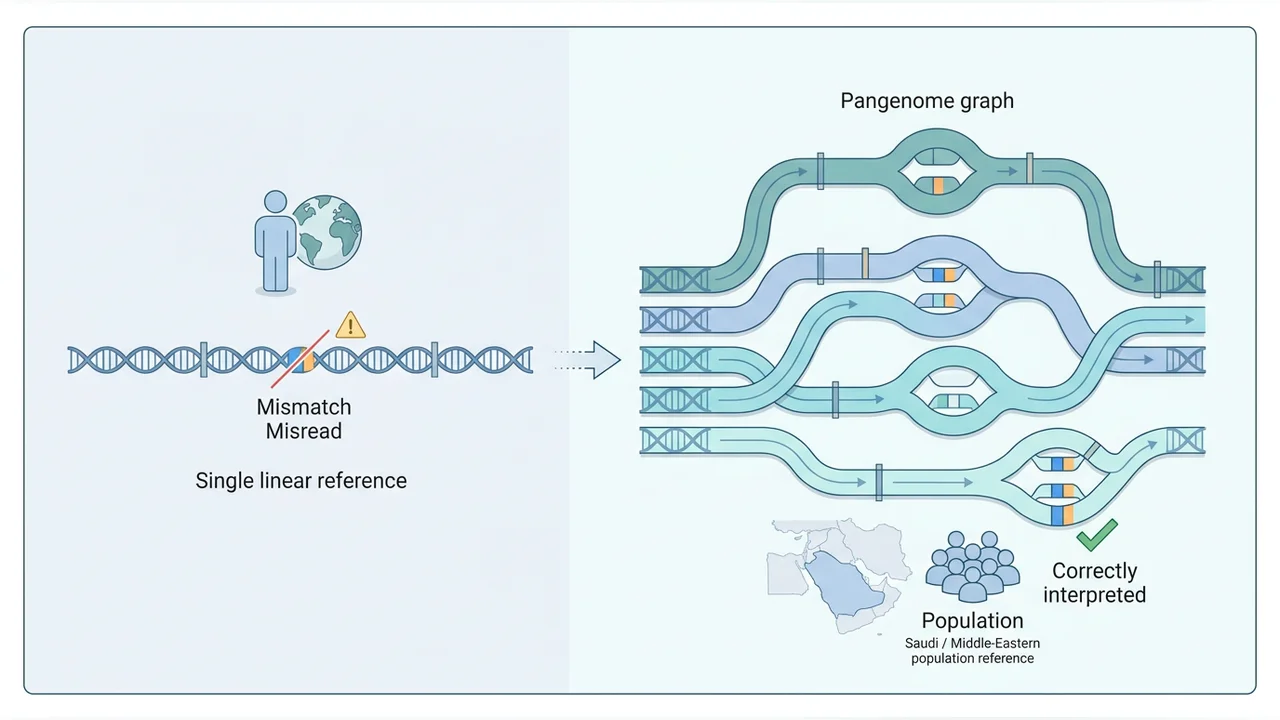
Human reference genomes such as GRCh38 are built largely from a single individual of mixed African-European ancestry, and they systematically misrepresent the genetic structure of populations that diverged from that backbone, especially populations like those of the Arabian Peninsula that were historically organized in tribal structures with high in-tribe marriage. The consequence in clinical practice is a reference bias that inflates the apparent variant count by millions, complicates interpretation, and lengthens diagnostic turnaround. With more than half of marriages in Saudi Arabia consanguineous (in some regions reaching 80 percent), and with sequencing established as a first-tier diagnostic test covered by the Ministry of Health, the cost of that reference bias is paid directly in Saudi clinics. This project, funded under the KAUST Smart Health Initiative (KSHI 2023) and running 2024-2026, aims to build a public Saudi pangenome as a reference for genomics across the Middle East.
The project follows three aims. First, ultra-high-molecular-weight DNA is extracted from blood samples of volunteers from geographically and tribally diverse regions of Saudi Arabia and sequenced on PacBio HiFi, Oxford Nanopore (with the Ultra-Long Sequencing Kit), Hi-C, and Illumina, providing the long, accurate reads required for telomere-to-telomere-style assembly. Second, diploid genome assemblies are produced with Hifiasm and scaffolded against KSA001 using MaSuRCA, and a pangenome graph is built that integrates the resulting genomes with the previously released KSA001 reference. Annotations are transferred from GRCh38 and CHM13 using LiftOff and LiftOver, and de novo annotations are produced using Augustus, Enformer, and SpliceAI. Third, the Saudi pangenome is evaluated as a reference for variant calling against GRCh38 and CHM13 on a clinically meaningful cohort, including hepatocellular carcinoma patients, with the explicit hypothesis that reference bias against the Saudi population is the dominant source of spurious variant calls.
The project builds on a direct line of prior results. A reference quality, fully annotated diploid genome from a Saudi individual (Scientific Data, 2024) delivered KSA001 as the first reference-quality diploid Saudi genome, and demonstrated that using KSA001 as a reference for Saudi individuals reduced the number of called variants by more than one million per genome compared to GRCh38. Phased genome assemblies and pangenome graphs of human populations of Japan and Saudi Arabia (Scientific Data, 2025) extends this to a phased, multi-individual pangenome graph and is the immediate methodological backbone of the project. The clinical-impact arm is informed by Genomic landscape in Saudi patients with hepatocellular carcinoma using whole-genome sequencing: a pilot study (Frontiers in Gastroenterology, 2023), which established the HCC cohort and demonstrated the kind of clinical genomics the pangenome is meant to support. Population-scale microbial genomics work in Genomic diversity and antimicrobial resistance of Staphylococcus aureus in Saudi Arabia: a nationwide study using whole-genome sequencing (Microbial Genomics, 2025) shows the same infrastructure being applied to public health surveillance at scale.
The expected outputs are a public Saudi pangenome graph derived from at least ten diploid assemblies, annotation transfer tools and chain files between the Saudi pangenome and GRCh38 or CHM13, standardized CWL workflows for variant calling against the pangenome, and evidence on a clinical cohort that pangenome-based calling reduces the variant load and improves interpretation. Beyond the immediate scientific deliverables, the project lays the infrastructure for clinical and commercial bioinformatics services in Saudi Arabia and the broader Middle East, where the pangenome can plausibly serve as the default reference for diagnostic sequencing.
Period: 2024–2026
Funding
- KAUST Smart Health Initiative
— Grant ID:
REI/1/5659-01-01(PI) — USD 210,000
Team
- Robert Hoehndorf — PI (KAUST (Professor of Computer Science))
- Malak Althagafi — CoI (Emory University)
- Yang Liu — PhD (alumnus)
Software
- DeepSVP — Prioritizes structural and copy-number variants by combining patient phenotype with gene-function similarity learned from biomedical ontologies. https://github.com/bio-ontology-research-group/DeepSVP
Publications acknowledging this project (2)
- (2025) Ontology Embedding: A Survey of Methods, Applications and Resources [live]
- (2024) Large-Scale Knowledge Integration for Enhanced Molecular Property Prediction [live]
Topics: Genomics, Neuro-symbolic AI, Rare disease
